Paolo Monella Risorse digitali per la ricerca classicistica
Questo capitolo 8.1 è stato curato da Paolo Monella e Gianni Sega. I paragrafi 8.1.1-8.1.15 sono di P. Monella; il paragrafo 8.1.16, di G. Sega.
8.1 Diogenes, versione 4
8.1.1 Nuova versione 4 del programma
Le istruzioni in questa pagina si riferiscono alla versione 4 del programma. Le vecchie istruzioni relative alla versione 3 si trovano in questa pagina. Per tutto ciò che non è coperto da questa pagina, fai riferimento alla vecchia versione delle istruzioni, dato che molte funzioni sono rimaste le stesse tra la versione 3 e la 4.
8.1.2 DiogenesWeb e Diogenes Desktop
Dalla home page del programma possiamo
- scaricare e installare la versione Diogenes Desktop sul nostro computer, oppure
- accedere alla versione online (DiogenesWeb) senza installare nulla sul nostro computer
DiogenesWeb effettua solo ricerche su corpora liberamente disponibili online (come il PHI per il latino), mentre Diogenes Desktop permette di effettuare ricerche sui corpora che abbiamo salvato sul nostro computer.
8.1.3 Installazione di Diogenes Desktop
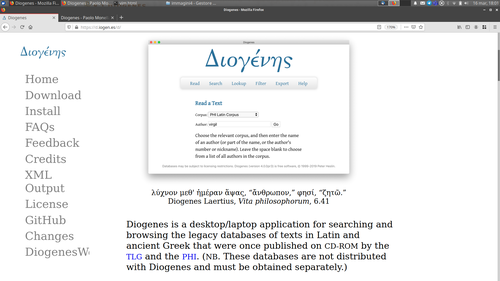
- Se clicchi su Diogenes Desktop, ci troviamo nella pagina mostrata nella Figura 2, dove troviamo il menu a sinistra
- Possiamo scaricare la nuova versione installabile Diogenes Desktop andando sulla pagina Download del menu a sinistra e scegliendo la versione relativa al nostro sistema operativo
- Nella pagina Install dello stesso menu di sinistra troviamo le istruzioni per l'installazione.
- Menu File in alto a sinistra → Database locations: clicca sul nome di ogni database (che ci interessa) per indicare al programma la cartella in cui si trova. Il programma chiama "database" quelli che io chiamo "corpora" (PHI 5.3 per il latino, TLG per il greco etc.)
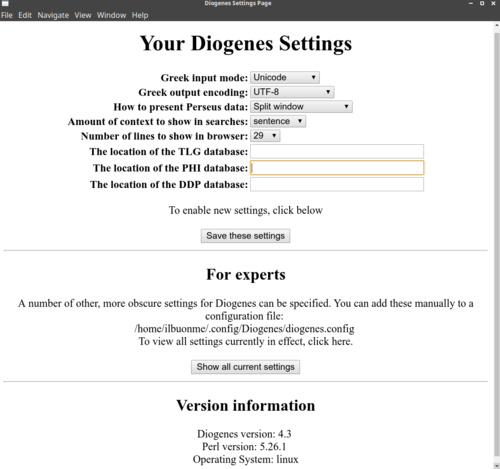
- Altre impostazioni relative al programma si possono modificare dal menu File → Other settings. La scheda Diogenes settings page (d'ora in poi pagina delle impostazioni) è rimasta più o meno la stessa di Diogenes 3: nella Figura 4 indico un possibile schema di configurazione (ignora le righe che iniziano con The location of..., per cui vedi il punto precedente)
- Diogenes include un ottimo font (Gentium), che comprende, tra l'altro, il greco polifonico, ed è impostato di default. La modifica del font era possibile in Diogenes 3 ed è di nuovo possibile nell'ultima release di Diogenes 4, andando sul menu File → Change font (non era possibile nella prima release di Diogenes 4).
- Nella pagina delle impostazioni, con l'opzione "number of lines to show in browser" si può decidere quante righe di testo vanno mostrate per pagina, quando si legge semplicemente un testo (modalità "browse").
- Terminata la configurazione, clicca su "save these settings". Quando appare la conferma Settings changed, puoi chiudere la finestra con la pagina delle impostazioni.
- Book (il libro del De oratore)
- Section (il paragrafo)
- Line (la riga all'interno dell'edizione a stampa di riferimento)
- AND (latino et, italiano e),
- OR (latino vel, italiano o),
- NOT (latino e italiano non).
- non troverei le forme al perfetto, dal tema "dux-" (che non includono la stringa "duc")
- troverei anche molte forme del sostantivo "dux, -ducis (m.)", del verbo "manduco, -as, -avi, -atum, -are" etc. (i cosiddetti "falsi positivi").
- duc: (pres imperat act 2nd sg)
- ducam: (fut ind act 1st sg) (pres subj act 1st sg)
- ducamque: (fut ind act 1st sg) (pres subj act 1st sg)
- Barra grigia → Lookup → Lexicon (cerca una parola nel dizionario – cioè nel Lewis-Short o nel Liddel-Scott): io inserisco una parola o una sua parte (stringa) nel campo Word, e Diogenes la cerca nel dizionario;
- Barra grigia → Lookup → Inflextion (fai l'analisi morfologica di una parola greca o latina): inserisco nel campo Word una parola intera o una sua parte (stringa) da analizzare;
- Barra grigia → Filter (crea e gestisci – sotto-corpora). I sotto-corpora sono gruppi di autori o opere all'interno dei quali fare poi ricerche specifiche. Ad esempio, potrei creare un gruppo comprendente Eschilo, Sofocle ed Euripide, per poi fare alcune ricerche lessicali solo nelle opere di questi tre autori. Un altro gruppo potrebbe comprendere tutto Tibullo, tutto Properzio e, di Ovidio, solo gli Amores.
- Furter narrow down to particular work of the select author
- Save the select authors as a subset for later use under this name
8.1.4 Configurazione di Diogenes Desktop
Dopo aver installato il programma, esso va configurato. D'ora in poi, le istruzioni non si riferiranno più al sito Web ma all'interfaccia del programma (vedi Figura 3). Io uso la versione per Linux, quindi alcuni menu potrebbero essere leggermente diversi sulle versioni per Mac o per altri sistemi operativi.
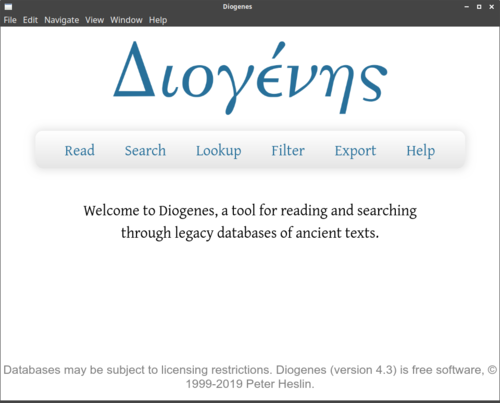
8.1.5 Menu e funzioni di Diogenes Desktop
Nei prossimi paragrafi parlerò delle funzioni attivabili a partire dalla barra su sfondo grigio con testo azzurro nella schermata principale del programma Diogenes Desktop (d'ora in poi barra grigia, vedi Figura 3). La schermata principale è raggiungibile in ogni momento dal menu Navigate → Home.
8.1.6 Barra grigia / Read (andare ad un passaggio specifico)
Per andare semplicemente andare ad un passaggio specifico, ad esempio al testo latino di Virgilio, Eneide, libro 2, verso 281, i passaggi sono questi:
Barra grigia / Read: si apre la finestra Read a text
Corpus: seleziona il corpus desiderato. Nel nostro esempio, trattandosi di un testo letterario latino, "PHI Latin Corpus". Se si fosse trattato di Sofocle, avrei scelto "TLG Texts"
Author: scrivi il nome dell'autore desiderato (o parte del nome), in latino (anche se si tratta di autori greci. Nel nostro caso, possiamo scrivere "Vergilius", "Verg", "Vergi", "verg", "vergil" etc. Se scriviamo semplicemente "verg", ci darà una lista di autori (o gruppi di opere) il cui nome comprende la stringa "verg" (vd. Figura 5):
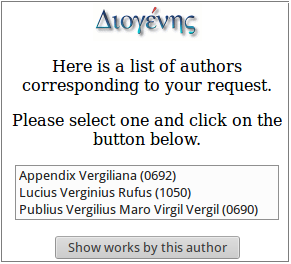
Seleziona l'autore desiderato dalla lista, in questo caso Publius Vergilius Maro Virgil Vergil (0690), e clicca su Show works by this author (mostra opere di questo autore).
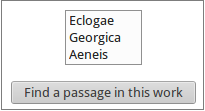
Apparirà una lista con le opere di quell'autore (nel nostro caso Eclogae, Georgica e Aeneis). Clicca sull'opera desiderata (per noi, Aeneis), e poi su Find a passage in this work (trova un passaggio in quest'opera), come nella Fig. 6:
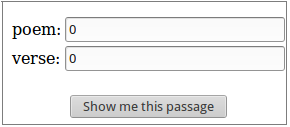
Appariranno due (o più) caselle vuote (vd. Figura 7), in cui inseriremo il libro (dell'Eneide) e il numero di verso a cui vogliamo andare. Noi scriveremo 2 nel campo book (il libro) e 281 nel campo verse (il verso), e cliccheremo su Show me this passage (mostrami questo passaggio).
Se si fosse trattato di un testo in prosa, i campi da riempire sarebbero stati diversi. Ad esempio, se avessimo sfogliato (sempre con browse) Cicerone → De oratore, i campi sarebbero stati:
Converrà semplicemente tradurre in italiano le indicazioni che il programma stesso dà, in alto, in questa pagina:
| Please select the passage you require by filling out the following form with the appropriate numbers; then click on the button below. | Seleziona il passaggio richiesto, compilando il modulo seguente con i numeri appropriati; quindi clicca sul bottone sotto. |
| (Hint: use zeroes to see the very beginning of a work, including the title and proemial material.) | (Suggerimento: inserisci zero per vedere l'incipit di un'opera, incluso il titolo e il materiale proemiale). |
Dopo aver cliccato su Show me this passage (mostrami questo passaggio), apparirà l'intero passaggio desiderato (vd. Figura 8):
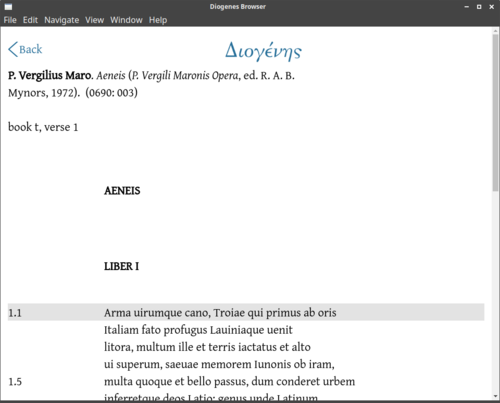
Specificamente, il verso richiesto sarà evidenziato in grigio. In alto, è leggibile l'edizione di riferimento.
Posso copiare/incollare porzioni di testo, ma non più di una pagina alla volta.
Coi tasti Move back (Vai indietro) e Move forward (Vai avanti) in basso, passo rispettivamente alla pagina precedente o alla successiva.
8.1.7 Numeri identificativi di autori e opere nel canone
Nella figura precedente, i due numeri alla fine dell'edizione (in questo caso, 0690 e 003) sono gli identificativi, all'interno del canone del corpus (PHI 5.3 o TLG), dell'autore (Virgilio, 0690) e dell'opera (tra le opere di Virgilio, 003 indica l'Eneide).
Quando ho iniziato lo "sfogliamento" (browse), nel campo Query, invece di "verg" o "Vergilius", avrei potuto inserire il suo codice (0690 o semplicemente 690).
8.1.8 Analisi morfologica e dizionario
Se clicco su una parola qualsiasi del testo latino o greco (ad esempio, su "lux" in Verg. Aen. 2.281), mi si apre a destra una finestra (vd. Figura 9) con le diverse possibilità di analisi morfologica (nel nostro caso, "lux" può essere sia maschile, sia femminile), e con il lemma "lux" nel dizionario Lewis-Short:

Diogenes usa il POS tagger, o parser (programma di analisi morfologica), del Perseus Project, e sempre dal Perseus prende le voci del Lewis-Short (per il latino) e del Liddel-Scott (per il greco).
Nell'angolo in alto a destra di questo riquadro: Dismiss serve a chiudere il riquadro stesso (sicché tutto lo spazio sia occupato dal solo testo latino/greco) Full screen serve a far sì che il riquadro occupi l'intero spazio (non si vedrà più il testo latino/greco, ma solo l'analisi morfologica e la voce del dizionario).
Nella figura precedente (lemma "lux" del Lewis-Short), è citato un passaggio antico: Plaut. Capt. 5, 4, 11. Queste citazioni ricorrono spesso nei lemmi di dizionario (in questo caso si tratta di una particolarità linguistica – "lux" al maschile; più spesso sono esempi di accezioni specifiche).
Un aspetto interessante è che se clicco su una di queste citazioni (ad es. su "Plaut. Capt. 5, 4, 11"), Diogenes mi rimanda direttamente a quel punto del Captivus di Plauto, di cui posso leggere anche il contesto.
In questo modo il lemma di dizionario diventa un ipertesto che rimanda direttamente ai testi, così come le singole parole dei testi rimandano ai lemmi del dizionario.
8.1.9 Ricerche lessicali
Si possono fare molte altre cose con Diogenes. Principalmente, cercare una parola specifica in tutto un corpus (ad es. "virgo" in tutto il corpus PHI 5.3, oppure "πόθος" in tutto il corpus TLG), o in una sotto-sezione di un corpus (ad es. "servitium" in Properzio e Tibullo).
Queste ricerche si attivano dalla barra grigia della schermata principale del programma, tramite il link Search.
Alcune delle funzioni di ricerca avrebbero bisogno di una trattazione dettagliata: spero di ampliare, prima o poi, questa sezione della guida. Ars longa, vita brevis.
Intanto, ecco le istruzioni fondamentali per questi tipi di ricerca.
8.1.10 Barra grigia / Search / Simple: Ricerca di una stringa (string matching)

Questa funzione (ricerca semplice di una parola o sequenza di parole) permette di cercare stringhe, ovvero pezzi di parola ("stringa" significa sequenza di caratteri).
Ad es., selezionando il Corpus PHI e scrivendo (nel campo Pattern) "virg" e cliccando su Go come nella Fig. 10, troverò tutti i passaggi che comprendono parole che comprendano le lettere "virg". Quindi, la parola virgo, -inis (f.), ma anche virginitas, -tatis (f).
Il termine tecnico per questo tipo di ricerca è string matching.
8.1.11 Barra grigia / Search / Within an author: Ricerca di stringa in un solo autore
È la stessa funzione del paragrafo precedente, ma posso specificare alcune lettere del nome di un autore nel campo Author per limitare la mia ricerca a quell'autore: ad esempio, se scrivo "senec" nel campo Author la ricerca sarà fatta sui due autori che hanno la stringa "senec" nel nome, cioè Lucius Annaeus Seneca senior e Lucius Annaeus Seneca iunior.
In realtà, però, il modo migliore per fare ricerche su autori o opere specifici è quello descritto più avanti, cioè l'uso della funzione Filter (dalla barra grigia della schermata principale di Diogenes Desktop).
8.1.12 Barra grigia / Search / Word list: Ricerca tramite la lista di parole del TLG
Cioè: cerca nel TLG usando la sua lista di parole. Funziona solo col corpus TLG.

Io inserisco una stringa greca (scritta in Unicode: se questo nome suona minaccioso, vd. questa guida), ad esempio "πόθο", nel campo Query, e Diogenes mi propone una lista di parole flesse (non lemmi) che possiedono quella stringa, tra cui ἱπποθόων, ποθουμένῃ, ἀειποθοῦς e decine di altre (vd. figura a destra, in cui ho riportato solo le prime righe della lista).
Io seleziono (cliccando sul quadratino corrispondente) le parole che voglio cercare.
Si tratta di una funzione ormai superata dalla Morfphological search di cui tratterò più sotto.
8.1.13 Barra grigia / Search / Multiple terms: Ricerca booleana di stringhe
Posso fare così una ricerca booleana di più stringhe, ovvero posso cercare due o più stringhe, collegate dai connettivi logici (studiati già dagli stoici):
Nel campo Query inserisco la prima stringa e clicco su Go. Mi si apre una finestra in cui inserisco le altre stringhe, i connettivi ed altri parametri.
Ci sarebbe molto da dire, qui: un dì, s'io non andrò sempre fuggendo di gente in gente, amplierò questo paragrafo.
8.1.14 Barra grigia / Search Inflected forms: Ricerca lemmatizzata
Posso ricercare così una parola sola, ma stavolta non come stringa (frammento di parola, sequenza di caratteri, come "virg" o "πόθο") bensì come lemma.
Per capirci, "virg" è una stringa, mentre "virgo, -inis (f.)" è un lemma, che include tutte le sue forme flesse, incluso "virginibus", "virgines" e anche "virginisque".
Qual è il vantaggio di questo tipo di ricerca rispetto alla Simple search for a word or phrase?
Se mi interessano le occorrenze di "duco, -is, -xi, -ctum, -ere", potrei cercare "duc" anche con la funzione Simple search for a word or phrase, però
Come fare, dunque, una Morphological search, ad es. sul lemma "duco, -is, -xi, -ctum, -ere"?

Dopo aver scelto da Corpus il corpus in cui fare la ricerca, inserisco alcune lettere del lemma che mi interessa, ad es. "duc", e clicco su Go.
Diogenes mi mostra ora una lista di possibili lemmi (non di forme flesse, come faceva con la funzione Search the TLG using its word-list, ma di lemmi). La lista per "duc" sarà molto lunga, e comprenderà lemmi come "Peducaeanus", "abduco", "abductio" etc. (vd. figura a sinistra).
Io scelgo il lemma che mi interessa, "duco" (cliccando sul quadratino corrispondente), e, più in basso, Show inflected forms (mostra forme flesse).
Diogenes a questo punto mi dà una lista delle forme flesse del verbo duco (vd. figura a destra), tra cui

e molte altre. Se mi vanno tutte bene (cioè voglio cercarle tutte), clicco semplicemente sulla riga Select all visible forms (seleziona tutte le forme visibili) e poi sul pulsante Search for inflected forms.
I passaggi latini che mi appariranno comprenderanno tutte e solo le forme verbali del verbo "duco, -is, -xi, -ctum, -ere", senza falsi positivi come "manducavimus" o "ducibus".
8.1.15 Altre funzionalità di Diogenes, in breve
Restano altre funzionalità di Diogenes da illustrare, e specificamente queste (sempre selezionabili dalla barra grigia):
Mentre le prime due funzioni (Look up a word... e Parse the inflection...) sono abbastanza semplici da usare, la terza (Manage user-defined corpora) lo è molto meno.
8.1.16 Barra grigia / Filter (creare sotto-insiemi del corpus)
Questo paragrafo 8.1.16 è opera di Gianni Sega.
Questa funzione permette di definire dei sotto-insiemi del corpus: ad esempio, un sotto-corpus che comprenda i soli elegiaci latini (quindi tutto Tibullo, tutto Properzio e solo gli Amores di Ovidio). O, come nell'esempio qui di seguito, i soli Annales di Tacito. Definito il sotto-corpus (o "corpus personalizzato"), in seguito potrò fare ricerche lessicali limitate ad esso (ad esempio, una certa parola solo negli elegiaci latini).
Partiamo dalla schermata iniziale, clicchiamo su Filter, quindi su Create and Manage Subsets.
Seguiamo un percorso per il latino (PHI Latin Corpus), ma i passaggi sono gli stessi anche per il greco (TLG Texts).
Scriviamo il nome dell’autore su cui operare la scelta, ad esempio, Tacito. Basta scrivere le prime lettere del nome (ad es. "tac"), e il sistema troverà automaticamente il resto.
Scegliamo di operare sulla collezione dei testi latini, cliccando ad esempio su PHI Latin Corpus nel menu a tendina che si apre sulla casella Database (se avessimo voluto operare sulla collezione dei testi greci, avremmo cliccato TLG Texts).
Quando si clicca su “Define subset”, il sistema individua due nomi:

La collezione contiene due autori Tacitus; selezioniamo il II: Cornelius Tacitus:

Ora si può scegliere una della due opzioni, indicate nella seconda parte della pagina:
Selezionando la prima opzione:
Furter narrow down to particular work of the select author
si intende procedere alla successiva scelta di una delle opere dell’autore; quindi, cliccando su “Proceed”, si apre un’altra pagina con tutte le opere di quell’autore, in questo caso di Tacito:

Ora selezioniamo una o più delle opere, scegliendo nella casella “Pleaase choose name…” il nome da assegnare al nuovo corpus. È bene scegliere un nome inequivoco, che contenga sia l’autore, sia l’opera (o le opere; perché ci sono altri che hanno scritto un’opera con questo titolo, e sarà bene che nell’elenco dei corpora in formazione, ad esempio l’eventuale scelta di Annales, riguardi solo quest’opera di Tacito). Il nome scelto può essere anche italiano: ad esempio: Tacito Annali, Tacito Annales, Tacitus Annales. Scegliamo Tacitus Annales:

Quindi cliccando su “Save”, il sistema memorizza il nome assegnato. Andiamo a controllare.
Andiamo sulla scritta greca azzurra Diogenes in alto (o su Navigate / Home dal menu in alto a sinistra).
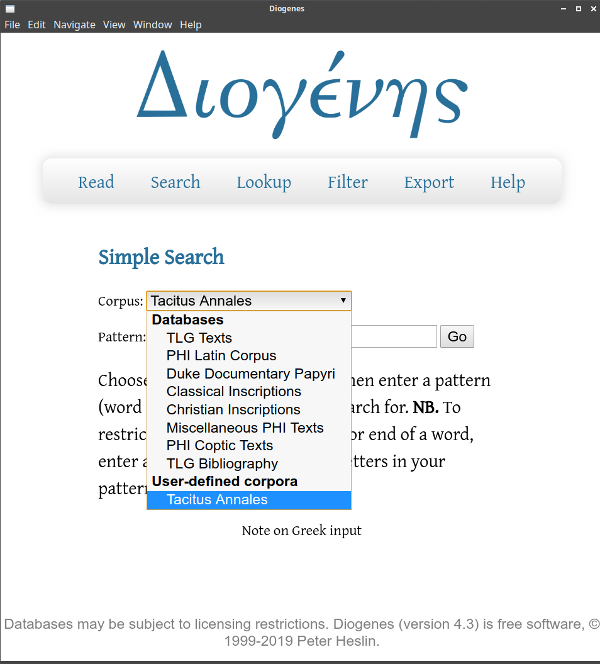
Si apre la pagina inziale. Se avviamo una qualunque ricerca (ad esempio con barra grigia / Search / Simple), possiamo controllare i vari corpora che si presentano nel menu a tendina Corpus. L’ultimo corpus della lista è quello appena costruito: Tacitus Annales.
Se invece si seleziona la seconda opzione:
Save the select authors as a subset for later use under this name
il corpus conterrà tutte le opere dell’autore e bisogna scegliere subito con quale nome designare il nuovo corpus. Trattandosi di tutte le opere di un autore, è bene indicarlo con una qualche specificazione. Restando su Tacito, si può scrivere: Tacito completo, Tacito full, Tacitus opera. Scegliamo: Tacito full.

Cliccando su Proceed, il sistema memorizza il nome assegnato.
Se, invece, volessimo cancellare dalla lista un corpus già definito, si deve ritornare alla schermata iniziale e selezionare come prima barra grigia / Filter / Create and Manage Subsets. Nella pagina che si apre, sezione List or modify an existing filter, ci sono le istruzioni per cancellare un corpus già definito. Cliccando sulla piccola freccia a destra della voce: Corpus, si apre un menu a tendina che mostra tutti i corpora già costruiti. Selezioniamone uno, ad esempio Tacitus full.
Ora si può operare in due modi. Questo è il primo.
1. cliccando su List contents, si individua nell’elenco degli autori, il nome “ufficiale” con cui la collezione testuale ha archiviato questo autore:

Il programma rileva che il nome da noi assegnato Tacitus full corrisponde all’autore Cornelius Tacitus. Spuntiamo il quadratino sulla sinistra del nome Cornelius Tacitus e clicchiamo su “Click here to delete selected items”:

Il sistema cancella il corpus.
Vediamo il 2° modo.
2. In Barra grigia / Filter / Create and Manage Subsets / sezione List or modify an existing filter, m scegliamo uno dei corpora già definiti dal menu a tendina che si apre cliccando sulla freccetta a destra e cliccare “Delete entire corpus”. Il sistema cancella il corpus che avevamo costruito con quel nome, senza ulteriori passaggi che individuino il nome “ufficiale” di quel corpus nella collezione testuale. In questo caso Tacitus full.
Se invece volessimo cambiare nome a un corpus già costruito; sempre in List or modify an existing filter c’è una opzione ad hoc: Duplicate corpus under new name:

Scegliamo, ad esempio, un nuovo nome per il corpus: Tacitus full. Scegliamo Tacitus opera omnia e lo scriviamo nella casella. Il sistema inserisce il corpus con questo nuovo nome.
Resta però il vecchio nome: Tacitus full, ancora funzionante, Ci sono, cioè, due nomi per lo stesso corpus. Ora si può cancellare Tacitus full …con la procedura vista prima, attraverso una delle due strade, ovvero List contents oppure Delete entire corpus:

Seguiamo ora il percorso analogo per scegliere un corpus definito entro la collezione dei testi greci: TLG Texts. Seguiamo nuovamente il percorso Barra grigia / Filter / Create and Manage Subsets. Scegliamo un autore greco che abbia scritto più opere, come Isocrate. Basta scrivere le prime lettere del nome, perché il sistema trova subito il riferimento:

cliccando “Define subset”, compaiono tutti i nomi che contengono “iso”:

Spuntiamo il primo: Isocrates Orat.

Poi, scegliamo la prima delle due strade:
Further narrow down to particular works of the selected authors

Cliccando “Proceed”, si apre un menu a tendina con l’elenco completo delle opere di Isocrate Oratore:
 |
 |
Ora si può selezionare l’opera e scegliere il nome del nuovo corpus nella casella che si trova in fondo alla finestra:

Cliccando “Save”, il nuovo corpus è costituito:
Se andiamo a controllare nella pagina iniziale, avviando una ricerca (ad esempio con barra grigia / Search / Simple), nella lista dei corpora, troveremo all’ultimo posto Isocrate De pace.
Se invece, a partire dalla pagina di scelta dei corpora:
Volessimo usare la seconda opzione:
Save the selected authors as a subset for later use under this name
Bisogna indicare nella casella sulla destra il nome da assegnare al nuovo corpus in formazione. Trattandosi di tutte le opere di Isocrate, è bene indicarlo con una formula adeguata, ad esempio Isocrate opera omnia:

Cliccando “Proceed”, il nuovo corpus è costituito.
La collezione dei testi greci, rispetto ai latini ha una opzione in più: le definizione di corpora secondari che raggruppino più autori per categorie.
Il percorso da seguire per questo è Barra grigia / Filter / Create and Manage Subsets / paragrafo Define a complex subset of the TLG. Quest'ultimo riguarda la scelta di corpora per categorie:
Cliccando su “Define a complex TLG corpus”…

Si arriva alla pagina di scelta delle categorie. Scegliamo dalla prima colonna: Author’s genre, gli storici (in latino: Historici), lasciando senza scelta tutte le altre categorie;

Cliccando poi in basso su “Get Matching Texts”, selezionando nella caselle a sinistra l’opzione “Any”. Si arriva nella pagina che contiene tutti gli storici. Si possono scegliere “tutti”, cliccando in fondo “Select All” e scrivendo il nome da assegnare a questo corpus complesso, ad esempio “Storici full”

Cliccando su “Save”, il nuovo corpus è costituito.
Se, invece, vogliamo inserire nel corpus solo alcuni storici, basta selezionarli:

e scegliere per loro il nome, nella casella in fondo:

Cliccando “Save”, il nuovo corpus è costituito

Quest'opera è distribuita con Licenza Creative Commons Attribuzione - Condividi allo stesso modo 4.0 Internazionale.